

Qua một khoảng thời gian dài, nhiều bạn feedback với mình là code trong bài viết Tập tành crawl dữ liệu product của Tiki không thể chạy được nữa. Không bất ngờ lắm với vấn đề này, mình sẽ hướng dẫn các bạn lấy lại dữ liệu về sản phẩm trên Tiki.
Code cũ đã không thể lấy được dữ liệu trên trang Laptop nữa, vì vậy chúng ta cần kiểm tra lại từ đầu xem Tiki đã thay đổi những gì trên website và API của họ.
Sau một hồi vọc vạch thì mình tìm thấy những thay đổi sau:
-
Trang web Laptop của Tiki đã đổi thành
và bạn không thể cào trang này nếu không cóuser-agenttrong header. Cái này thì mình có thể làm dễ ẹc 😀 -
Thay đổi lớn hơn đó là trang web Laptop của Tiki đã dùng API để lấy danh sách sản phẩm, và tất nhiên bạn có thể dùng API đó để lấy
Product IDthay vì phải đọc từng trang web. Lại còn dễ dàng hơn phải không 😀
API để lấy danh sách sản phẩm của Tiki cũng tương tự API lấy thông tin một sản phẩm:
Việc lấy danh sách sản phẩm bằng API này có thể không trả về đầy đủ thông tin mà các bạn cần, nên nếu muốn lấy đầy đủ thông tin thì cứ gọi lại API lấy thông tin một sản phẩm.
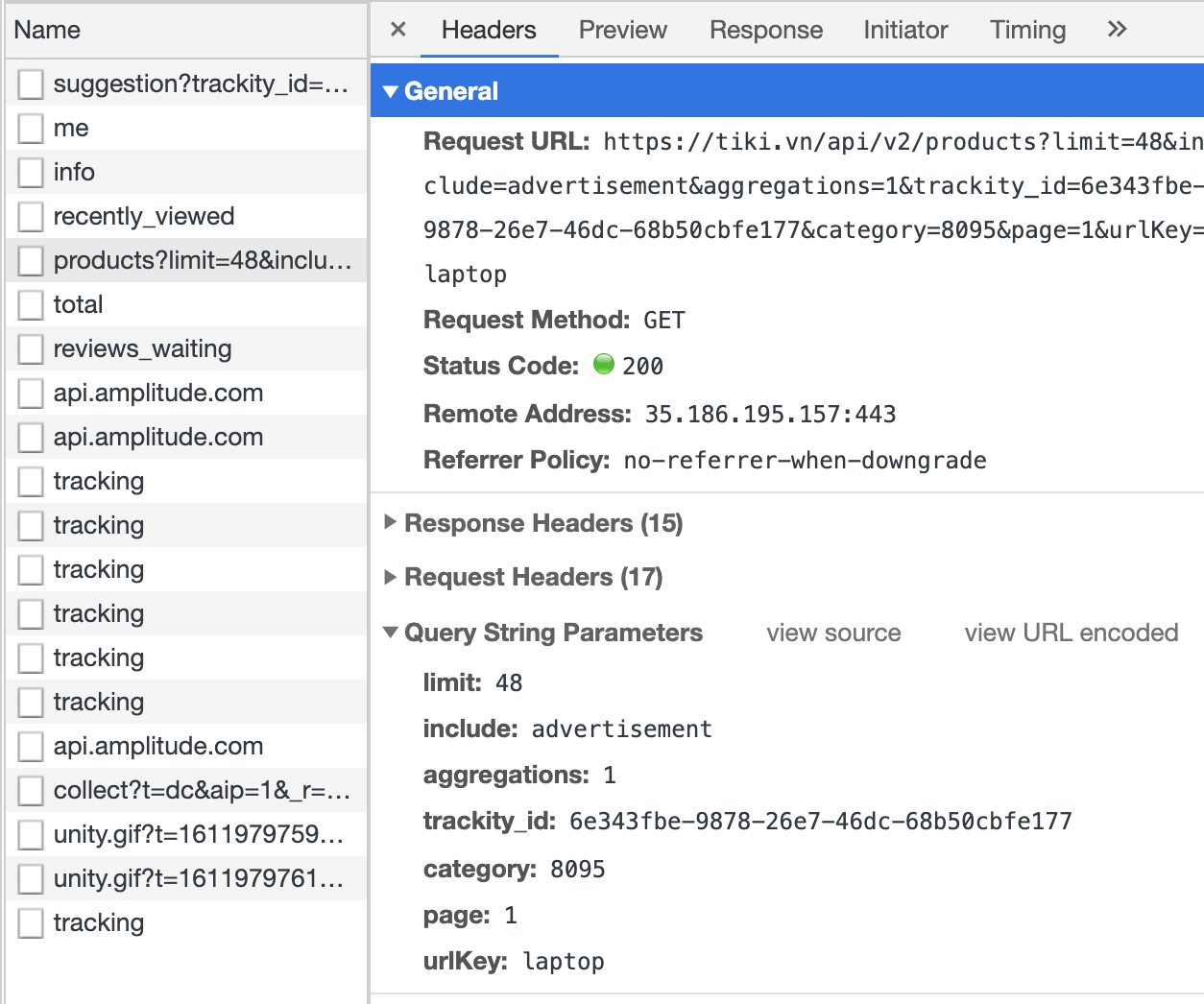
Đích thị là nó 😀
Tuy nhiên, để gọi được API này thì bạn cũng cần thêm user-agent vào header nhé. Nếu không bạn sẽ nhận lỗi 403: Permission Denied.
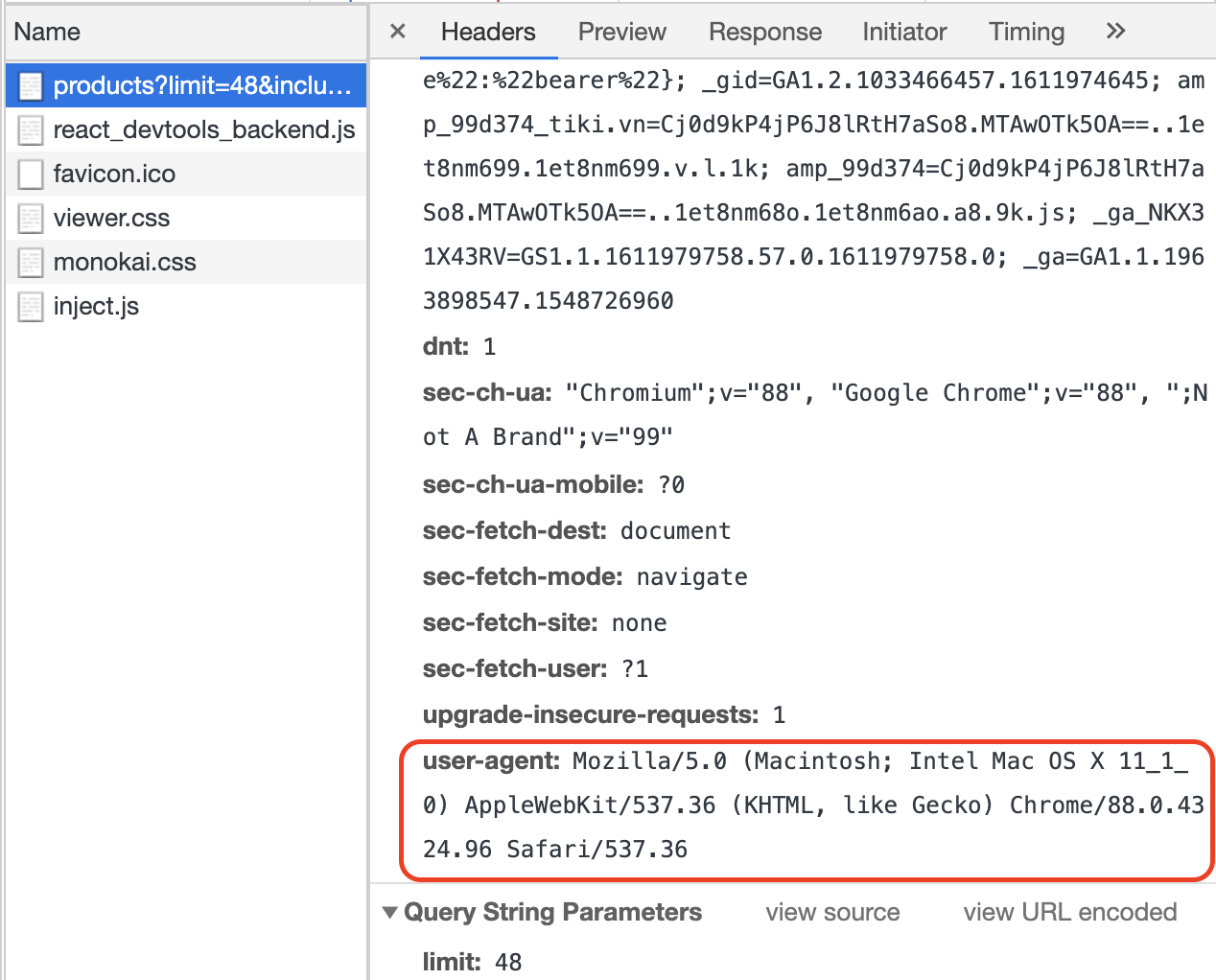
Cũng cần `user-agent` cho API này
Tóm lại, sau khi kiểm tra lại trang Tiki, chúng ta có thể thấy:
- API lấy thông tin một sản phẩm vẫn giữ nguyên.
- Bạn không cần phải cào từng trang web để lấy danh sách sản phẩm nữa mà chỉ cần dùng API lấy danh sách sản phẩm là xong.
- API lấy danh sách sản phẩm đã trả khá nhiều dữ liệu, nếu dữ liệu đã đủ phục vụ nhu cầu của bạn thì chúng ta không cần dùng API lấy thông tin một sản phẩm. Trong hướng dẫn phía sau, mình vẫn muốn lấy đầy đủ thông tin sản phẩm nên mình vẫn sẽ sử dụng API lấy thông tin một sản phẩm.
- Cần có
user-agentcho các API này.
Trước tiên, sửa lại một số xử lý. Mình sẽ vẫn lấy hết Product ID để lưu lại rồi lấy thông tin chi tiết từng Product ID sau.
Định nghĩa header:
headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"}
Sửa lại tí nè, thêm header, gọi API thay vì dùng BeautifulSoup.
def crawl_product_id():
product_list = []
i = 1
while (True):
print("Crawl page: ", i)
print(laptop_page_url.format(i))
response = requests.get(laptop_page_url.format(i), headers=headers)
if (response.status_code != 200):
break
products = json.loads(response.text)["data"]
if (len(products) == 0):
break
for product in products:
product_id = str(product["id"])
print("Product ID: ", product_id)
product_list.append(product_id)
i += 1
return product_list, i
def save_product_id(product_list=[]):
file = open(product_id_file, "w+")
str = "n".join(product_list)
file.write(str)
file.close()
print("Save file: ", product_id_file)
# crawl product id
product_list, page = crawl_product_id()
print("No. Page: ", page)
print("No. Product ID: ", len(product_list))
# save product id for backup
save_product_id(product_list)
Sửa lại một chút, thêm header ở hàm lấy thông tin một sản phẩm.
def crawl_product(product_list=[]):
product_detail_list = []
for product_id in product_list:
response = requests.get(product_url.format(product_id), headers=headers)
if (response.status_code == 200):
product_detail_list.append(response.text)
print("Crawl product: ", product_id, ": ", response.status_code)
return product_detail_list
Các bước còn lại tương tự như bài viết trước.
Xem toàn bộ source code ở đây nhé:
Việc một hệ thống thay đổi kiến trúc, thay đổi API khiến mình không thể crawl dữ liệu được nữa là việc hết sức bình thường. Điều quan trọng ở đây là việc phân tích vấn đề để tìm ra giải pháp cho vấn đề đó.
Trong tương lai Tiki có còn thay đổi nữa không? Chắc chắn có.
Có phải Tiki chặn crawl dữ liệu do bài viết trước hay không? Có thể có mà cũng có thể không. Phần nhiều dựa vào đánh giá rủi ro của họ khi chúng ta crawl dữ liệu. Nếu rủi ro cao, họ sẽ thêm nhiều cơ chế bảo mật hơn thì chúng ta cũng phải vất vả hơn để vượt qua cơ chế đó.
#Tập #tành #crawl #dữ #liệu #product #của #Tiki #Phần
![[👨💻🇻🇳] Tập tành crawl dữ liệu product của Tiki (Phần 2)](https://i1.wp.com/2023-data-image.dreamhosters.com/wp-content/uploads/sites/3/2024/07/143298868_115630627127590_9069119239345556836_n.jpg?w=840&resize=840,1120)
![[👨💻🇻🇳] Tập tành crawl dữ liệu product của Tiki (Phần 2)](https://i1.wp.com/2023-data-image.dreamhosters.com/wp-content/uploads/sites/3/2024/05/142116237_3603217889799095_1669580485937244367_n.jpg?w=750&resize=750,500)
![[👗🇻🇳] IVY moda – Chuỗi thương hiệu thời trang công sở 👕 Top1Fashion 👗 – New Arrival: Sơ mi Grace x Chân váy tweed
Sự kết hợp hoàn hảo giữa áo sơ mi các …](https://i0.wp.com/2023-data-image.dreamhosters.com/wp-content/uploads/sites/3/2024/09/460044434_927493252745997_3467836758117151314_n.jpg?w=336&resize=336,220)
![Hạt é kỵ với gì? Lợi ích của loại hạt nhỏ mà “có võ” [🆕🇻🇳] bazaarvietnam.vn](https://i0.wp.com/2023-data-image.dreamhosters.com/wp-content/uploads/sites/3/2024/09/2024_shop1_top1vietnam_top1list_top1index_harper-bazaar-hat-e-ky-voi-gi-4.jpg?w=336&resize=336,220)
![[🆕🇻🇳] [HOT] Cập nhật “diện mạo” của iPhone 16 mới ra mắt của Apple](https://i2.wp.com/2023-data-image.dreamhosters.com/wp-content/uploads/sites/3/2024/09/2024_shop1_top1vietnam_top1list_top1index_Dien-mao-iphone-16.jpg?w=336&resize=336,220)
![[🆕🇻🇳] Có nên nâng cấp iPhone 15 Pro lên iPhone 16 Pro?](https://i0.wp.com/2023-data-image.dreamhosters.com/wp-content/uploads/sites/3/2024/09/2024_shop1_top1vietnam_top1list_top1index_Iphone_16_gia_bao_nhieu.jpg?w=336&resize=336,220)
